I started using AI coding tools sometime in 2024. At first, that mostly meant Cursor-style code completion: useful, occasionally surprising, but not yet the kind of agentic workflow where I could hand over a repository-level task and expect sustained progress.
Then the tools became more agentic. The models were not strong enough yet, but the interaction pattern changed. I could ask for bigger changes. The agent could edit several files. It could follow a plan, run tests, and try again.
That made me faster. It also made some projects messier.
Across consulting projects and astronomy side projects, I kept seeing the same code failure mode. Similar helpers would appear in multiple places. Slightly different versions of the same validation path would accumulate. One agent would solve a local problem without noticing that another version of the solution already existed elsewhere in the repository.
The documentation problem was related, but different. I was also experimenting with spec-driven development using coding agents, which meant the repository filled up with requirements notes, design notes, implementation plans, research notes, and status documents. Those documents often described overlapping pieces of the same feature, but not always in the same way. Some were current. Some were half-obsolete. Some were useful only because they preserved the intent behind a decision.
By late 2025, coding agents crossed an inflection point. Around November 2025, they became strong enough that the problem changed. It was no longer just “agents create messy code.” The better question became:
How do I give a strong agent the right slice of the repository so it can clean things up without wasting context on everything else?
On May 1, 2026, I published dryscope to PyPI. It is my attempt to answer that question.
The name is a conflation of DRY (“Don’t Repeat Yourself”) and telescope. DRY gives the target: repeated code, repeated explanations, and overlapping knowledge. Telescope gives the posture: look across a large repository and bring the interesting parts into view before deciding what to clean up.
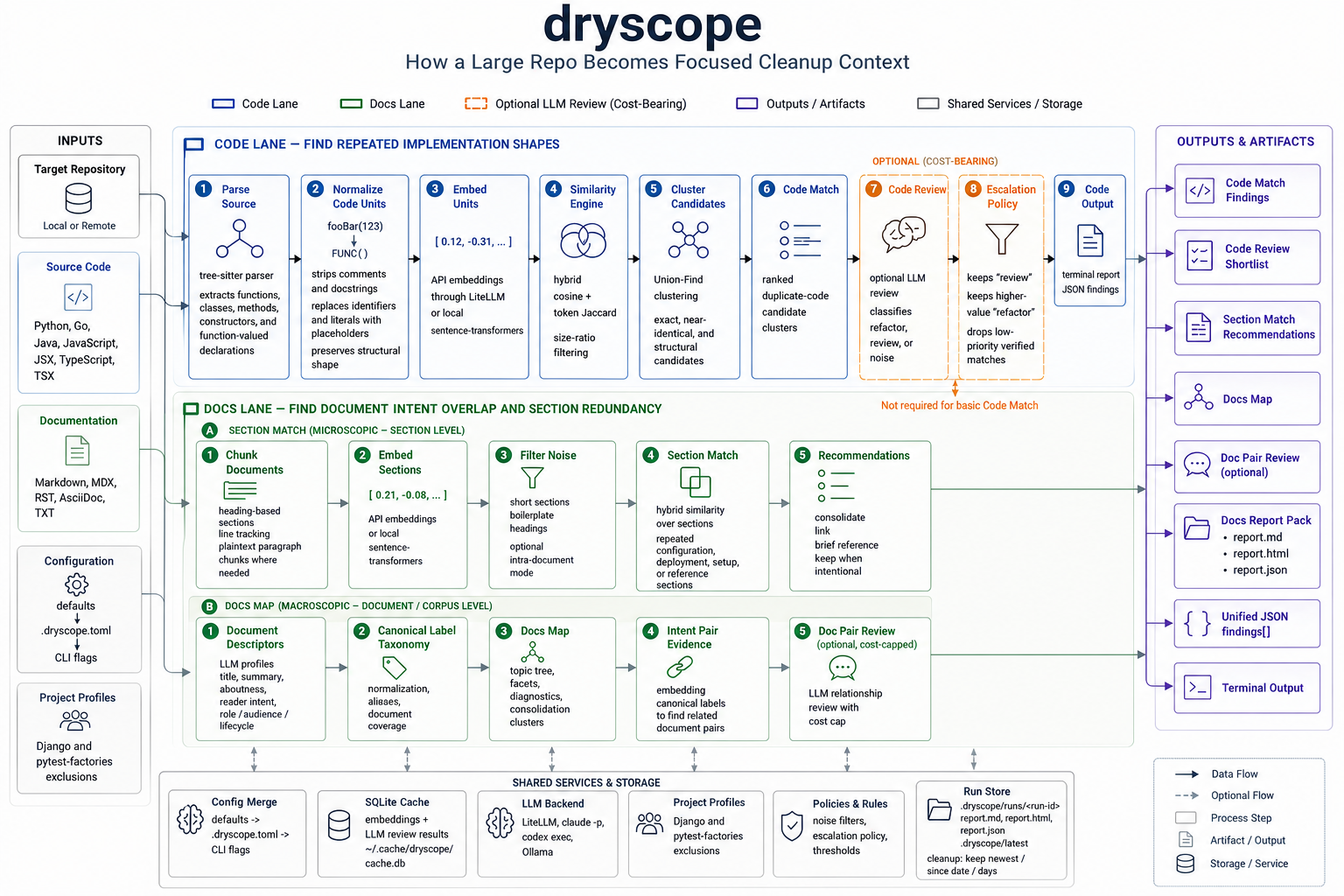
dryscope scans a repository and produces a shortlist: duplicate-code candidates, repeated documentation sections, and documentation intent overlap. It does not rewrite your code or decide the refactor for you. The point is narrower and more practical: before I ask an agent, stronger model, or human reviewer to clean up a repo, show me the files and sections worth reading first.
Repository: github.com/kvsankar/dryscope
The Problem
Large-repo cleanup often starts with a vague instruction:
Clean up the duplication in this project.
That sounds reasonable, but it is underspecified. A large repository has too much surface area. The agent has to decide which directories matter, which repeated code is real duplication, which repeated code is test scaffolding, and which docs are current enough to trust.
If the agent starts in the wrong place, it burns context before it reaches the useful part of the project.
There are two related problems here: documentation context and code duplication. The documentation problem usually shows up first because spec-driven AI-assisted development creates many documents before, during, and after implementation.
A project may contain:
- product requirements
- architecture notes
- research notes
- implementation plans
- status updates
- generated summaries
- ADRs or half-ADRs
Those documents are not always textually duplicated. The overlap is often about intent. Two documents may both describe the same feature, but one frames it as requirements, another as design, and another as rollout status. If I hand all of them to an agent, the model gets an unfocused pile of partially overlapping context instead of one clear source of truth.
The code problem is the second half of the same context-management issue. Agent-assisted development makes it cheap to solve a local problem again. That is convenient in the moment, but over time similar logic appears in commands, services, parsers, UI branches, tests, and migration scripts.
I wanted a narrowing pass before the cleanup pass.
From doclens To dryscope
The first version of this idea was not about code. It was a small project called doclens.
doclens started as a documentation overlap detector. The earliest version used normalized compression distance as a fast first filter, then embeddings and LLM analysis for the pairs that survived. That was useful for finding repeated or near-repeated content, but it missed the more important problem: two sections can be about the same thing without saying it the same way.
The first step change was making embeddings the primary filter. The early design used a progressive pipeline: normalized compression distance first, API embeddings second, and LLM analysis after that. In doclens v0.5, I replaced that with a Model2Vec embeddings-first pipeline. That made the tool closer to how I already thought about retrieval-augmented generation: turn text into vectors, compare meaning, and use the closest matches as candidate context.
But pairwise similarity alone was not enough. A pile of similar section pairs is still a pile. The output had to answer practical questions:
- Is this a repeated explanation that should become one canonical section?
- Are these two documents serving different readers and both worth keeping?
- Is one document current while the other is historical?
- Is this exact text overlap, or broader intent overlap?
That pressure pushed the project from raw matching toward reports, labels, and judgment.
The second step change was adding code. dryscope grew beyond documentation and started parsing source code with tree-sitter. Instead of comparing whole files, it extracts code units: functions, classes, methods, constructors, and function-valued declarations.
The third step change was information architecture. Documentation overlap was not just “section A resembles section B.” I needed a Docs Map: document descriptors, canonical labels, topic groups, facets, diagnostics, and consolidation clusters.
That is when doclens effectively became one part of dryscope.
How The Code Path Works
The code pipeline is intentionally boring in the right places.
First, dryscope parses source files with tree-sitter. It currently supports Python, Go, Java, JavaScript, JSX, TypeScript, and TSX. The parser extracts code units rather than treating a file as one blob.
Then it normalizes each code unit. Comments and docstrings are removed. Identifiers and literals are replaced with placeholders. The goal is to make this kind of clone visible:
def load_user_config(path):
raw = path.read_text()
return json.loads(raw)
def load_project_config(file_path):
content = file_path.read_text()
return json.loads(content)
Those functions are not textually identical, but structurally they are the same operation.
After normalization, dryscope embeds each unit and compares candidates with a hybrid score: embedding cosine similarity plus token Jaccard similarity, with size-ratio filtering so tiny helpers do not get matched against much larger functions. Candidate pairs are clustered with Union-Find and reported as exact, near-identical, or structural matches.
That gives a Code Match report.
Raw similarity is not enough, so there is an optional Code Review pass. That sends candidate clusters to an LLM reviewer and classifies them as:
refactorreviewnoise
Then a deterministic escalation policy keeps all review findings and only keeps higher-value refactor findings. This matters because the enemy is not missing every possible duplicate. The enemy is handing the next agent a noisy list that causes another context burn.
How The Docs Path Works
The docs path has two related but separate ideas.
Section Match works at the microscopic level. It chunks Markdown, MDX, RST, AsciiDoc, and plaintext documents by headings, embeds the sections, and finds repeated or near-repeated section-level material across documents using embedding similarity.
For example, a requirements document and a design document may both contain a Configuration section explaining the same environment variables. Those documents should not necessarily be merged, but the repeated section may need one canonical reference.
Docs Map works at the corpus level. It asks a different question:
What are these documents about, what reader intent do they serve, and where do they overlap in purpose?
For each document, dryscope can extract descriptors such as title, summary, aboutness labels, reader intents, document role, audience, lifecycle, content type, surface, and canonicality. Those raw labels are normalized into a corpus-level taxonomy.
A small example:
| Document | Raw signal |
|---|---|
docs/search-requirements.md | search filters, ranking expectations, user-visible behavior |
docs/search-design.md | indexing pipeline, query API, architecture |
research/vector-search.md | embeddings, retrieval quality, ranking experiments |
plans/search-rollout.md | rollout checklist, status, risks |
Docs Map can turn that into canonical labels like:
| Area | Example labels |
|---|---|
| Aboutness | search experience, indexing pipeline, ranking quality, vector retrieval |
| Reader intent | define requirements, explain architecture, compare approaches, track rollout |
| Facets | doc_role: requirements/design/research/plan, lifecycle: current/draft, audience: maintainer/agent |
| Cluster | documents that should share a source of truth or cross-reference each other |
That distinction matters. Section Match says, “these sections repeat.” Docs Map says, “these documents are trying to describe overlapping parts of the same system.”
Both are useful before giving context to an agent.

Why Not Just Ask The Agent?
You can ask an agent to inspect a repository and find duplication. I do that too.
But repository-wide inspection is exactly where context management matters. The agent has to choose what to read before it knows what matters. It may spend most of its budget on framework boilerplate, generated files, examples, test fixtures, stale notes, or low-value similarity.
dryscope tries to make that first pass cheaper.
It uses deterministic parsing, normalization, filtering, and clustering before optional LLM judgment. The LLM is not the whole product. It is one review stage after cheaper signals have narrowed the candidate set.
That design is deliberate. I do not want a tool that says, “here is the final refactor.” I want a tool that says:
Start here.
These files probably deserve attention first.
These docs probably overlap in purpose.
These findings are likely noise.
That is a better handoff to a coding agent.
Benchmarks As Design Pressure
I added public benchmark runs because it is too easy to fool yourself with examples.
The benchmark report in the repository is careful about what it claims. The labels are sparse. Unlabeled surfaced findings are not counted as false positives. The numbers describe a reviewed slice of benchmark output, not the universe of every possible duplicate in every repo.
The current aggregate looks like this:
| Track | TP | FP | FN | Labeled precision | Curated recall | F1 |
|---|---|---|---|---|---|---|
| Code Review | 11 | 7 | 2 | 0.61 | 0.85 | 0.71 |
| Section Match | 3 | 3 | 0 | 0.50 | 1.00 | 0.67 |
That is not a victory lap. It is a useful alpha signal.
For the workflow I care about, recall and precision have different meanings. Recall matters because I want the shortlist to catch the real cleanup candidates. Precision still matters because every false positive wastes attention. The current state is exactly what I would expect from a public alpha: useful enough to narrow a repo, not clean enough to trust blindly.
Some public validation examples were encouraging:
| Repo | Structural candidates | Verified shortlist from top 15 |
|---|---|---|
CLI-Anything-WEB | 94 | 5 |
nanowave | 82 | 10 |
ClaudeCode_generated_app | 51 | 6 |
VibesOS | 23 | 4 |
The important thing is not the raw candidate count. It is that a duplicate-rich repo can be reduced to a review queue small enough for a human or agent to inspect.
Packaging Was Product Work
The publish-readiness phase surfaced a very practical issue.
At one point, a fresh wheel install pulled in the full local embedding stack, including PyTorch and NVIDIA wheels. That may be acceptable for someone who explicitly wants local sentence-transformer embeddings. It is not acceptable as the default install path for a CLI that someone may want to try quickly.
So the default package now supports API embeddings through LiteLLM, and local embeddings live behind an optional extra:
uv tool install "dryscope[local-embeddings]"
pipx install "dryscope[local-embeddings]"
python -m pip install "dryscope[local-embeddings]"
That was a good reminder: for developer tools, packaging is part of the product. If the first install feels surprising, users may never reach the interesting part.
Getting Started
For a one-off run:
uvx dryscope --help
uvx dryscope scan .
For a persistent tool install:
uv tool install dryscope
dryscope --help
Or with pipx:
pipx install dryscope
dryscope --help
The default embedding model uses API embeddings through LiteLLM. Set the provider API key for the embedding model you use, such as OPENAI_API_KEY for text-embedding-3-small.
Some useful commands:
# Code Match
dryscope scan /path/to/project
# Code Review
dryscope scan /path/to/project --verify --max-findings 15
# Section Match for docs
dryscope scan /path/to/docs --docs
# Full docs report pack
dryscope scan /path/to/docs --docs --stage docs-report-pack --backend cli -f html
# Agent-friendly JSON
dryscope scan /path/to/project -f json
What I Think It Is
dryscope is not a linter. It is not a perfect semantic clone detector. It is not a replacement for code review. It is also not a refactoring oracle.
It is a narrowing tool.
That framing matters because AI-assisted development has made it easier to create more code and more documentation than we can comfortably keep in our heads. Stronger agents help, but they still need context. If the context is duplicated, stale, scattered, or too broad, the agent spends effort reconstructing the project before it can improve it.
I built dryscope to make that first step more explicit:
- scan the repo
- find likely repeated implementation shapes
- find repeated sections
- map overlapping documentation intent
- hand the shortlist to a human or agent
The goal is not to remove judgment. The goal is to spend judgment where it has leverage.
That is the part of AI coding I am most interested in right now. Not just asking better prompts, and not pretending agents can hold an entire project in working memory. The useful layer is tooling that shapes the context before the agent starts.
dryscope is my first public alpha in that direction.
Discussion
- GitHub: kvsankar/dryscope
- PyPI: dryscope